
5. Datenreduktion beim digitalen Videosignal
Die Übertragung des digitalen Video-Studiosignals über gegebene Breitbandkanäle beim Austausch von Programmbeiträgen zwischen den Rundfunkanstalten („Contribution“) sowie bei der Zuführung des Programmsignals zu den Sendestationen und insbesondere aber bei der Verteilung des Programmsignals zu den Fernsehteilnehmern („Distribution“) erfordert eine beträchtliche Datenreduktion. Für den Programmaustausch und die Versorgung der Sendestationen stehen im wesentlichen Digitalverbindungen mit den standardisierten Bitraten innerhalb der Plesiochronen Digitalen Hierarchie (PDH) (nach ITU-T für Europa) mit 8,448 Mbit/s, 34,368 Mbit/s und 139,264 Mbit/s bzw. Synchronen Digitalen Hierarchie (SDH) mit 155,52 Mbit/s zur Verfügung [18].
Die aufgeführten Bitraten werden auch im paketorientierten ATM-Übertragungs- verfahren (Asynchronous Transfer Mode) genutzt. Dieses Verfahren ermöglicht im Gegensatz zu den fest geschalteten Verbindungen eine bedarfsgesteuerte Zuordnung von Übertragungskapazität. Über spezielle Verbindungen, meist Glasfaserleitungen, wie z. B. beim Hybnet der ARD-Sender [70,72], findet auch ein Austausch von Programmbeiträgen mit dem Digitalen Studiosignal DSC 270 Mbit/s statt. Zukünftig wird die Verteilung des datenreduzierten Studiosignals mit 50 Mbit/s über LANs (Local Area Network) an Bedeutung gewinnen. Digitale Übertragungskanäle können nur mit einer festen, vorgegebenen Bitrate betrieben werden, weil empfangsseitig eine auf diese Bitrate abgestimmte Taktrückgewinnung stattfindet.
5.1 Prinzipien der Datenreduktion
Eine Datenreduktion kann auf dem Weg der Redundanzreduktion oder Irrelevanzreduktion erfolgen. Redundanzreduktion bedeutet das Herausnehmen von überflüssiger, weil bereits bekannter Information. Bei der Irrelevanzreduktion erfolgt ein Weglassen von unwesentlicher und meist vom menschlichen Sinnesorgan (Auge, Ohr) nicht wahrnehmbarer Information. Redundante Information findet sich beim Videosignal in nebeneinander oder übereinander liegenden Bildpunkten (spatiale Redundanz) und vor allem in aufeinanderfolgenden Teilbildern bzw. in Ausschnitten derselben (temporale Redundanz).
Es ist deshalb naheliegend, nur den Signalinhalt zu übertragen, der sich bezogen auf vorangehende Bildpunkte (spatial oder temporal), geändert hat. Der unveränderte Signalanteil wird jeweils einem Speicher entnommen. Eine Redundanzreduktion hat keinen Informationsverlust zur Folge. Man spricht deshalb auch von einer verlustlosen Codierung.
Irrelevante Information liegt beim Videosignal in einer hohen Chrominanzauflösung und in den Details der Bilder. Wie schon im Abschnitt 2.3.4 aufgeführt, hat das menschliche Sehorgan eine geringere Auflösung für Farbdetails im Vergleich zu Helligkeitsänderungen. Dem wird beim digitalen Video-Studiosignal mit dem 4:2:2-Abtastraster bereits Rechnung getragen. Darüber hinaus wird auf die Tatsache Bezug genommen, dass im Spektrum eines realen Videosignals die höheren Frequenzkomponenten zunehmend mit geringerer Amplitude vertreten sind und deshalb eine reduzierte Auflösung vertretbar ist. Im Zusammenhang mit der Analog-Digital-Wandlung käme dies einer zu höheren Signalfrequenzen hin größeren Quantisierung gleich. Eine Irrelevanzreduktion hat einen, wenn auch meist nicht wahrnehmbaren, Informationsverlust zur Folge. Es liegt deshalb eine verlustbehaftete Codierung vor.
5.2 Verfahren der Redundanzreduktion
Zugrunde liegt das Prinzip der „Differenzübertragung“, das schematisch in Bild 5.1 dargestellt ist. Einem zeitabhängigen Signal s(t) werden aufeinanderfolgend „Proben“ (Abtastwerte) entnommen. Jeweils ein vorangehender Abtastwert (n-1) aus dem Speicher bzw. dem „Prädiktor“ T wird mit dem aktuellen Wert (n) verglichen. Die Differenz d(n) wird dem Empfänger übertragen und dort zu dem ebenfalls gespeichert vorliegenden Abtastwert (n-1) addiert. Es handelt sich um eine „verlustlose“ Signalübertragung [19].
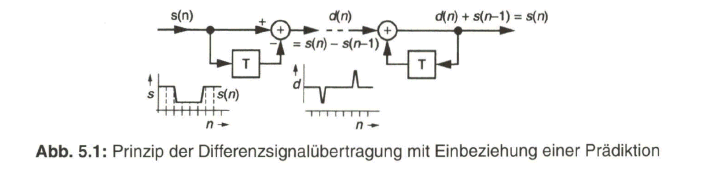
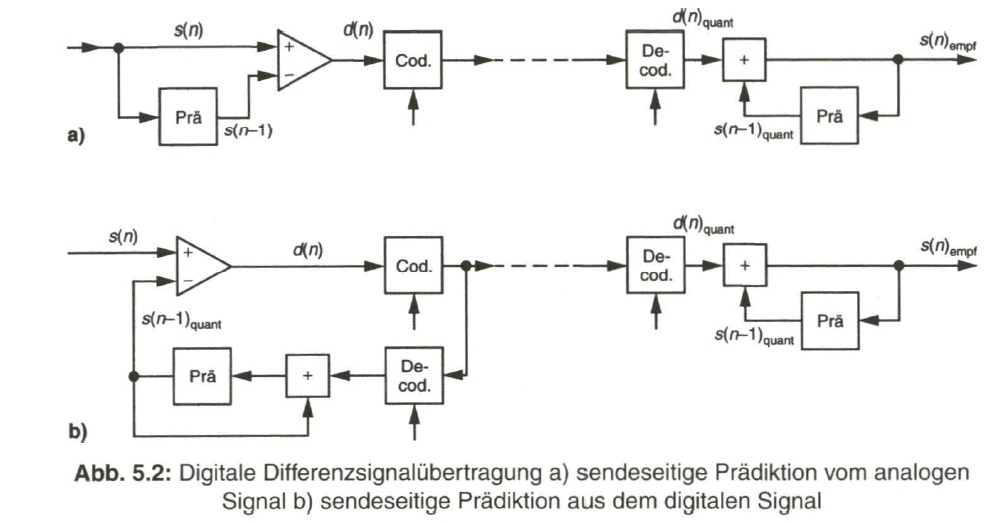
Zusammenhang mit digitaler Signalübertragung wird das zu übertragende Differenzsignal (n) in einem Encoder analog-digital gewandelt sowie empfängerseitig in einem Decoder wieder digital-analog gewandelt (Bild 5.2a). Dabei zeigt sich nun, dass auf der Sendeseite die Prädiktion (n-1) aus dem analogen Eingangssignal ![]() entnommen wird, aber das rekonstruierte Empfangssignal s(n)empf auf einem Vorhersagewert (Prädiktion) s
entnommen wird, aber das rekonstruierte Empfangssignal s(n)empf auf einem Vorhersagewert (Prädiktion) s![]() basiert, der mit dem Quantisierungsfehler des Encoders behaftet ist [20]. Damit wären sendeseitige und empfangsseitige Prädiktion unterschiedlich und es würde zu einer Fehlerfortpflanzung führen. Um dem zu begegnen, wird auch sendeseitig der aus dem Empfangssignal abgeleitete Wert s
basiert, der mit dem Quantisierungsfehler des Encoders behaftet ist [20]. Damit wären sendeseitige und empfangsseitige Prädiktion unterschiedlich und es würde zu einer Fehlerfortpflanzung führen. Um dem zu begegnen, wird auch sendeseitig der aus dem Empfangssignal abgeleitete Wert s![]() als Prädiktion verwendet (Bild 5.2b). Man kommt so zum Verfahren der Differenz-Pulscodemodulation (DPCM) mit prädiktiver Codierung [20].
als Prädiktion verwendet (Bild 5.2b). Man kommt so zum Verfahren der Differenz-Pulscodemodulation (DPCM) mit prädiktiver Codierung [20].
5.2.1 Anwendung der Differenz-Pulscodemodulation (DPCM)
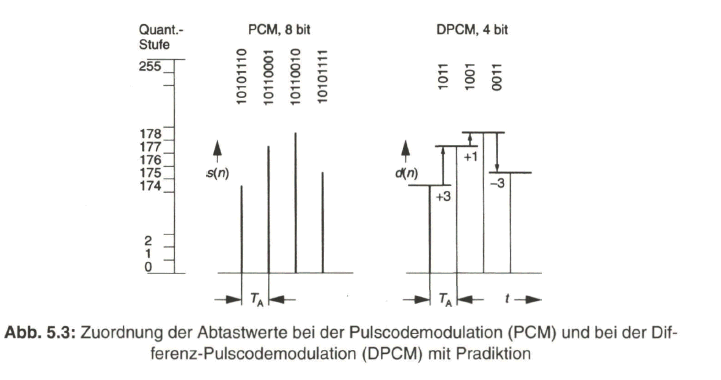
Die statistische Auswertung der Differenzwerte d(n) eines Videobildes zeigt, dass der Wert Null am häufigsten vorkommt und die Wahrscheinlichkeit mit zunehmen dem Differenzwert, positiv oder negativ, sehr schnell absinkt. Es wird deshalb nicht der gesamte Quantisierungsbereich codiert, sondern nur ein kleinerer Bereich für die Differenz werte mit dem Ergebnis, dass die Codewortlänge kürzer und damit die zu übertragende Bitrate geringer wird. Bild 5.3 zeigt dies an einem Beispiel mit Gegenüberstellung der Codierung bei der Pulscodemodulation (PCM) und bei der Differenz-Pulscodemodulation (DPCM).
Der DPCM-Codiervorgang geht von einem „Startwert“ aus, der voll codiert wird (PCM). In gewissen Abständen wird ebenfalls jeweils ein PCM-codierter „Stützwert“ eingefügt, um die Abweichung des rekonstruierten Signals vom Originalsignal zu minimieren.
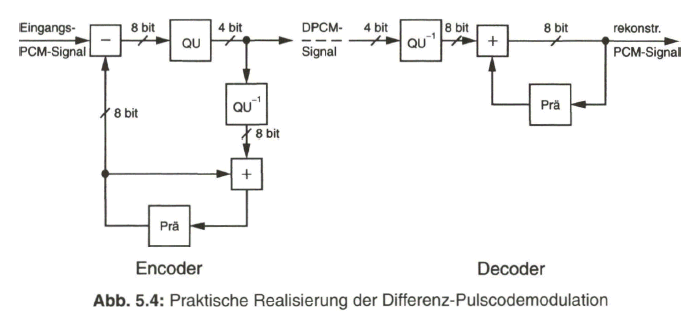
Die praktische Realisierung der DPCM erfolgt über digitale Signalverarbeitung, da ja das Videosignal bereits in digitaler Form vorliegt. Aus dem PCM-Signal, dem digitalen Leuchtdichtesignal Y oder den digitalen Chrominanzsignalen ![]() bzw.
bzw. ![]() mit einer Codewortlänge von z. B.
mit einer Codewortlänge von z. B. ![]() bit wird über digitale Subtraktion des Prädiktionssignals ein Differenzsignal
bit wird über digitale Subtraktion des Prädiktionssignals ein Differenzsignal ![]() mit
mit ![]() bit berechnet, das dann in einer nachfolgenden Quantisierung (Q) auf eine Wortbreite von
bit berechnet, das dann in einer nachfolgenden Quantisierung (Q) auf eine Wortbreite von ![]() bit reduziert wird. Dieses DPCM-Codesignal wird dem Empfänger zugeführt und dort über eine „inverse Quantisierung“
bit reduziert wird. Dieses DPCM-Codesignal wird dem Empfänger zugeführt und dort über eine „inverse Quantisierung“ ![]() in ein 8-bit-Codewort umgewandelt und in die Prädiktionsschleife eingeführt. Dieser Vorgang geschieht auch auf der Sendeseite zur Rekonstruktion des Prädiktionssignals. Siehe dazu Bild 5.4.
in ein 8-bit-Codewort umgewandelt und in die Prädiktionsschleife eingeführt. Dieser Vorgang geschieht auch auf der Sendeseite zur Rekonstruktion des Prädiktionssignals. Siehe dazu Bild 5.4.
Aus der Grundidee des DPCM-Verfahrens ist zu entnehmen, dass die zu übertragende Information im Differenzsignal (n) umso geringer ist, je näher der Prädiktionswert (n-1) an den tatsächlich vorliegenden Signalwert (n) herankommt, das heißt je besser die Prädiktion ist. Geht man von der konstanten Codewortlänge ab und ordnet den häufig vorkommenden geringen Differenzwerten kurze Codeworte zu, im Gegensatz zu längeren Codeworten für die nur selten vorkommenden größeren Differenzwerte, so ergibt sich bereits eine beträchtliche Datenreduktion. Ziel ist nun, eine Prädiktion bei den Abtastwerten zu gewinnen, die der aktuellen Situation am nächsten kommt.
Eine Prädiktion beim Videobild kann abgeleitet werden aus benachbarten Bildpunkten innerhalb einer Zeile (eindimensionale Prädiktion) oder unter Bezugnahme auf benachbarte Bildpunkte in der vorangehenden Zeile desselben Halbbildes oder Vollbildes (zweidimensionale Prädiktion, als „Intrafield-Prädiktion“ oder „Intraframe-Prädiktion“). In Bildbereichen ohne Bewegung erhält man die beste Voraussage durch den Bildpunkt an der gleichen Stelle im vorangehenden Vollbild (Interframe-Prädiktion). Diese Prädiktion wird jedoch dann zu Fehlern führen, wenn sich der Bildinhalt bei bewegten Vorlagen von Teilbild zu Teilbild ändert. Es wird deshalb zunächst der gesamte Bereich des aktiven Bildes, mit z.B. 720 x 576 Pixel, in kleine Ausschnitte unterteilt und die Änderung innerhalb dieser Ausschnitte untersucht.
In Verbindung mit dem MPEG-2-Standard, der später im Abschnitt 7.2 ausführlich behandelt wird, bezeichnet man einen solchen „Ausschnitt“, der üblicherweise den Bereich von 16x16 Pixel abdeckt, als Makroblock. Das aktive Bild mit 720 x 576 Pixel wird damit in
(720 : 16) X (576 : 16) = 45 x 36 = 1620 Makroblöcke
unterteilt.
5.2.2 Differenzbildübertragung mit Bewegungskompensation
Zur Verbesserung der Prädiktion erfolgt nun in den Makroblock-Ausschnitten eine so genannte Bewegungskompensation (Moving compensation). Es wird zunächst der Makroblock-Ausschnitt, im Folgenden als „Musterblock“ bezeichnet, des aktuellen (Voll-)Bildes mit dem korrespondierenden Musterblock des vorangehenden (Voll-)Bildes verglichen, indem ein Summenwert der Beträge der Differenz in den einzelnen Bildpunkten des Musterblocks berechnet wird: Displaced Frame Difference, DFD. Durch bildpunktweises Verschieben des Musterblockes aus dem vorangehenden Bild in horizontaler und vertikaler Richtung und jeweils erneutes Berechnen der DFD wird die Position des Musterblocks aus dem vorangehenden Bild gesucht, bei der die DFD am geringsten ist. Die Verschiebung des Musterblocks wird durch die Bewegungsvektoren Delta ![]() und Delta
und Delta ![]() ausgedrückt. Der Vorgang zur Ermittlung dieser Bewegungsvektoren wird als Bewegungsschätzung (Motion estimation) bezeichnet. Die Prädiktion zu den Bildpunkten aus dem aktuellen Musterblock liefern nun die Bildpunkte des Musterblocks aus dem vorangehenden (Voll-) Bild, verschoben um die berechneten Bewegungsvektoren Delta X und Delta Y (Bild 5.5). Auf diese Weise wird das bewegungskompensierte Bild blockweise dem aktuellen Bild weitestgehend ähnlich. In Bild 5.5 ist das übertragene Teilbild
ausgedrückt. Der Vorgang zur Ermittlung dieser Bewegungsvektoren wird als Bewegungsschätzung (Motion estimation) bezeichnet. Die Prädiktion zu den Bildpunkten aus dem aktuellen Musterblock liefern nun die Bildpunkte des Musterblocks aus dem vorangehenden (Voll-) Bild, verschoben um die berechneten Bewegungsvektoren Delta X und Delta Y (Bild 5.5). Auf diese Weise wird das bewegungskompensierte Bild blockweise dem aktuellen Bild weitestgehend ähnlich. In Bild 5.5 ist das übertragene Teilbild ![]() als voll übertragendes „Stützbild“ angenommen. Die verbleibende zu übertragende Differenz-Information ist nun wesentlich geringer als die Information aus den Original-Musterblöcken. Wegen der „blockweisen“ Anpassung des Bildinhaltes spricht man auch von Blockmatching.
als voll übertragendes „Stützbild“ angenommen. Die verbleibende zu übertragende Differenz-Information ist nun wesentlich geringer als die Information aus den Original-Musterblöcken. Wegen der „blockweisen“ Anpassung des Bildinhaltes spricht man auch von Blockmatching.

Der Rechenaufwand bei diesem Verfahren ist zunächst sehr hoch. Mit einem Suchbereich von ±16 Pixel horizontal und ±8 Pixel vertikal und den Rechenoperationen Subtraktion und Betragsbildung, sowie Addition der absoluten Differenzen führt das zu
(45 x 36 Makroblöcke/Bild) x (32 x 16 Suchpositionen/Makroblock) x (16 x 16 Pixel/Makroblock) x (3 Rechenoperationen/Pixel) x (25 Bilder/s)
= 16 Milliarden Rechenoperationen/s.
Mit intelligenten Rechenverfahren ist eine Verringerung möglich. Die Musterblock-Größe mit 16 x 16 Pixel stellt einen Kompromiss zwischen möglichst guter Prädiktion und möglichst geringer Datenmenge des Differenzbildes dar. Je kleiner der Musterblock ist, umso besser wird die Prädiktion, aber der Rechenaufwand steigt an.
Mit größerem Musterblock sinkt zwar der Rechenaufwand, aber die Prädiktion wird schlechter. Der Suchbereich hängt von der maximalen Bewegungsgeschwindigkeit der Bildszene ab, meist wird dafür eine Bildbreite/s angenommen. Die Grenzen des Suchbereiches werden darauf bezogen üblicherweise mit ±16 Pixel horizontal und ±8 Pixel vertikal festgelegt. Je kleiner die Schrittweite bei der Suche nach dem Minimum der DFD ist, desto genauer werden die ermittelten Bewegungsvektoren. Es wird deshalb auch mit „half-pixel-Schritten“ gearbeitet. Das durch die Bewegungskompensation ergänzte Blockschaltbild des DPCM- Encoders und -Decoders zeigt Bild 5.6. Auf der Empfangsseite entfällt die aufwändige Berechnung der Bewegungsvektoren. Vielmehr werden diese über datenreduzierte Codeworte zusammen mit dem eigentlichen Differenzsignal übertragen.
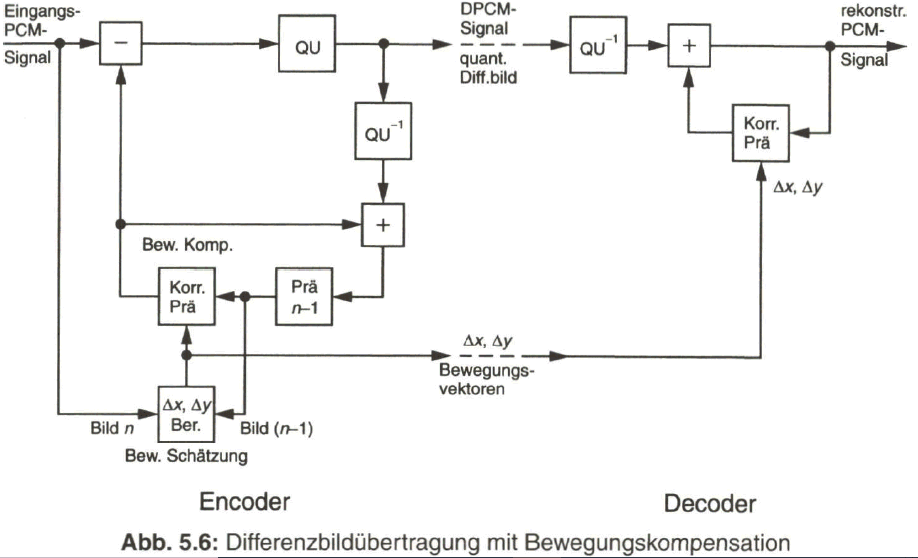
Die Differenzübertragung mit Bewegungskompensation bewirkt eine Datenreduktion bis etwa um den Faktor vier, abhängig vom Bildmaterial.
5.3 Verfahren der Irrelevanzreduktion
Die Irrelevanzreduktion beim Videosignal nimmt Bezug auf gewisse Unvollkommenheiten des menschlichen Auges. Dies gilt auch für die mit feineren Bildstrukturen nicht mehr wahrnehmbaren Quantisierungsverzerrungen. Eine Umsetzung dieser Tatsache in eine technische Realisierung könnte bei einem analogen Videosignal so erfolgen, indem das Videofrequenzband über Bandpässe in mehrere Teilbereiche aufgespaltet wird, deren Signale mit zunehmender Mittenfrequenz bei der Analog-Digital-Wandlung grober quantisiert werden. Das Verfahren wäre sehr aufwändig und insbesondere bei schmalen Bandpässen sehr problematisch hinsichtlich der dabei auftretenden Gruppenlaufzeitverzerrungen. Eine elegantere Lösung bietet sich mit dem digitalen Videosignal und digitaler Signalverarbeitung durch Verlagerung des Aufwandes in die Software-Ebene. Zur Anwendung kommt dabei eine Transformationscodierung mit Codierung im Frequenzbereich. Von verschiedenen Möglichkeiten hat sich bei Videosignalen als günstigstes Verfahren die Diskrete Cosinus-Transformation (DCT) erwiesen. Die Diskrete Cosinus-Transformation (DCT) ist eine nahe Verwandte der Diskreten FOURIER-Transformation (DFT), aus deren Ergebnis der Cosinus-Anteil übernommen wird, was bei dem mathematischen Verfahren der „schnellen“ Diskreten FOURIER-Transformation (FDFT) zu Vereinfachungen führt.
5.3.1 Anwendung der Diskreten Cosinus-Transformation (DCT)
Die Zuordnung des Bildinhaltes auf eine Vielzahl von „Teilfrequenzbereichen“ erfolgt nun unter Bezugnahme auf so genannte „Basismuster“. Dazu wird die Bildvorlage wiederum in kleine Ausschnitte unterteilt, die mit dem aus dem MPEG-2- Vokabular vorweggenommenen Ausdruck „Block“ bezeichnet werden. Die Blockgröße beträgt üblicherweise 8 x 8 Pixel. Die „Intensitätsverteilung“ (Leuchtdichte /oder Chrominanzanteil CB bzw. CR) in jedem Block wird dann interpretiert durch eine gewichtete Überlagerung der Basismuster, die mit Koeffizienten (Adresse und Intensität) in codierter Form ausgedrückt werden. Man verwendet 8 x 8 = 64 Basismuster, die in horizontaler und vertikaler Richtung steigend feiner strukturiert sind und so einen Bezug auf eine Vielzahl von „Teilfrequenzbereichen“ erlauben. Die bei der DCT verwendeten Basismuster sind in Bild 5.7 wiedergegeben.

In der linken oberen Ecke findet sich das homogene Basismuster, mit dem die mittlere Helligkeit (DC) im Block angegeben wird. Von dort bzw. von den Mustern in der linken Spalte nach rechts gerichtet wird die Horizontalauflösung feiner und von der oberen Zeile nach unten gerichtet wird die Vertikalauflösung feiner. In der Diagonale ist deutlich die ansteigende Strukturauflösung zu ersehen. Den Basismustern wird eine Gewichtung über 64 Intensitätsstufen zwischen den Helligkeits- (Intensitäts-) Grenzen „weiß“ und „schwarz“ zugeordnet.
Das Videobild mit 720 x 576 Pixel (für Luminanz Y) wird unterteilt in (720 : 8) x (576 : 8) = 90 x 72 = 6480 Blöcke mit jeweils 8 x 8 Pixel. Jeder Block wird dann in seinem Bildinhalt verglichen mit den 64 Basismustern und „synthetisiert“ durch die Überlagerung der gewichteten Basismuster, die durch ihre Koeffizienten Fuv angegeben werden. Die Umsetzung der Helligkeitsverteilung Y (x,y) eines 8 x 8-Pixel-Blocks in die 8x8 Koeffizienten der Basismuster durch die DCT bzw. die Rückumsetzung der Koeffizienten in die Helligkeitsverteilung durch die Inverse DCT zeigt prinzipiell Bild 5.8.
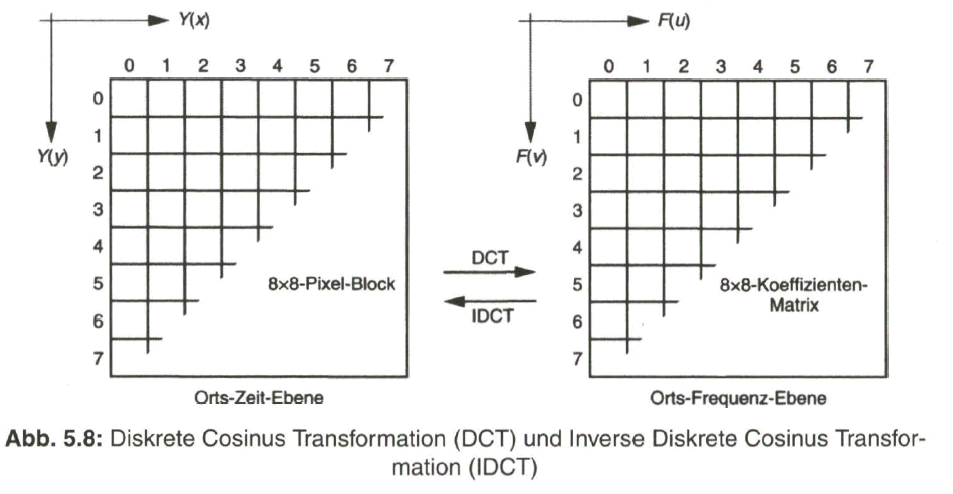
Die Koeffizienten ![]() der Basismuster sind in einer 8x8-Matrix abgelegt. Die Zuordnung zwischen den Basismustern und den Koeffizienten zeigt ausschnittsweise Bild 5.9
der Basismuster sind in einer 8x8-Matrix abgelegt. Die Zuordnung zwischen den Basismustern und den Koeffizienten zeigt ausschnittsweise Bild 5.9
Für die Diskrete Cosinus-Transformation der Intensitätsverteilung Y (x,y) = f (x,y) aus dem Orts-Zeit-Bereich in den Orts-Frequenz- bzw. Orts-Koeffizienten- Bereich F (uv) gilt die Rechenvorschrift:
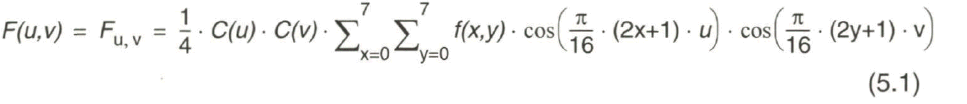
Das Eingangssignal F (x,y) liegt aus einem 8x8-Pixel-Block mit x, y = 0,1,2, 3,4, 5, 6, 7 vor.
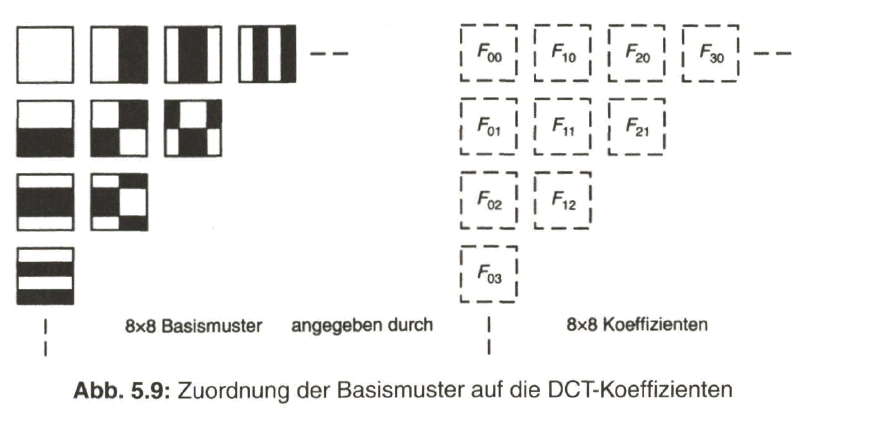

Die Orts-Frequenzen der Koeffizienten-Matrix werden angegeben mit u, v= 0, 1,
2, 3,4, 5, 6, 7.
An einem Beispiel mit den aus [24] entnommenen Zahlenwerten sei die DCT mit den nachfolgenden Schritten zur Datenreduktion nun demonstriert.
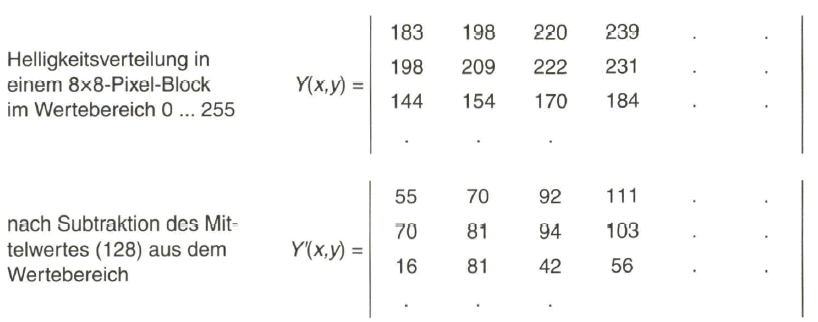
Als Vorbereitung für die Irrelevanzreduktion erfolgt nun die Diskrete Cosinus- Transformation, mit Bezug auf die Basismuster und Angabe der DCT-Koeffizienten F(u,v)
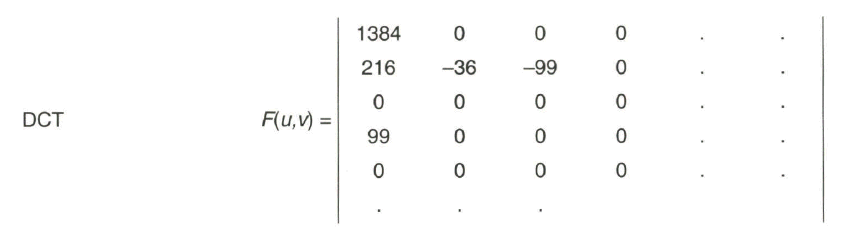
Der DC-Koeffizient wird mit höherer Genauigkeit angegeben
5.3.2 Frequenzabhängige Quantisierung
Mit dem nächsten Schritt wird eine frequenzabhängige Quantisierungstabelle Q(u,v) eingebracht,


Nach Rundung (INT) erhält man QF'(u, v) zu

Es zeigt sich, dass viele der Koeffizienten zu Null werden, was die Möglichkeit einer datenreduzierten Übertragung der Koeffizienten erschließt.
5.4 Redundanzreduktion beim Datenstrom durch Lauflängencodierung (RLC) und Variable Längen Codierung (VLC)
Als Vorbereitung für die Datenreduktion wird über ein Zick-Zack-Auslesen das Umsortieren derquantisierten und gerundeten Koeffizienten vorgenommen. Man erhält damit aus der Matrix. Als Vorbereitung für die Datenreduktion wird über ein Zick-Zack-Auslesen das Umsortieren derquantisierten und gerundeten Koeffizienten vorgenommen. Man erhält damit aus der Matrix
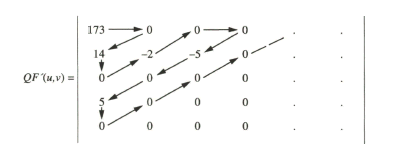
die Koeffizienten in der Reihenfolge
173 0 14 0-2 00-5 05 00 0 . . .
Diese Koeffizientenfolge wird nun einer Redundanzreduktion unterzogen, über eine Lauflängencodierung, Run Length Coding (RLC) mit zwei Ziffern. Dabei gibt die erste Ziffer die Länge der ununterbrochenen Folge von Nullen vor dem Wert an, der gleich der zweiten Ziffer selbst ist. Am Ende der Koeffizientenfolge aus der Zick-Zack-Abtastung befindet sich meist nur noch eine lange Folge von Nullen. In diesem Fall wird das „end of block“-Codewort ausgegeben und der Decoder weiß, dass nur noch Nullen folgen. Es folgt eine weitere Redundanzreduktion über eine Entropie-Codierung als Variable-Längen-Codierung, Variable Length Coding (VLC).
Dabei werden mit Hilfe von HUFFMAN-Tabellen häufig vorkommende Codewort- Kombinationen in kürzere Codeworte und weniger häufig vorkommende Kombinationen in längere Codeworte umgesetzt. Insgesamt ergibt sich eine beträchtliche Reduktion der Datenmenge, Das Prinzip der variablen Längen-Codierung liegt bereits dem MORSE-Alphabet zu Grunde.
Koeffizientenfolge nach der Zick-Zack-Abtastung:
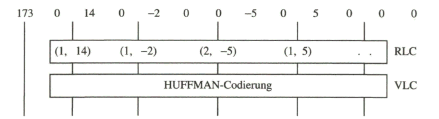
Der DC-Koeffizient (im Bereich 0 ... 511) wird mit 9 bit direkt codiert.
Die Variable-Längen-Codierung mit HUFFMAN-Tabellen wird auf Lauflängen und Amplitudenwerte im Bereich 0 ... 15 angewendet. Für Kombinationen, die nicht in der auf diesen Bereich bezogenen Tabelle enthalten sind, wird die Codierung der Lauflänge und der Amplitude mit fester Codewortlänge vorgenommen. Für diesen Fall muss den beiden Codewörtern eine eindeutige Markierung vorangestellt werden, damit der Decoder erkennt, dass auf diese Codewörter nicht die Huffmann-Tabelle angewendet werden darf.
Bei der Wahl der Blockgröße ist abzuwägen, dass bei zu großen Blöcken verschiedene Bildinhalte an den Blockgrenzen nach der Quantisierung in den Nachbarblock übersprechen können und ein sehr hoher Rechenaufwand erforderlich wird. Bei zu kleinen Blöcken aber werden die Nachbarschaftsbeziehungen im Block nur wenig ausgenutzt. Eine Blockgröße von 8x8 Pixel hat sich bei der DCT als optimal erwiesen, Bei der unabhängigen Codierung benachbarter Bildblöcke können teilweise noch durch die Unstetigkeiten an den Blockgrenzen sichtbare Plattenstrukturen auftreten. Man bezeichnet dies als „Blocking-Effekt“.
Die Datenreduktion über
• DCT, mit Quantisierung und Rundung, als Irrelevanzreduktion,
• Zick-Zack-Auslesen der Koeffizienten und
• RLC sowie VLC, als Redundanzreduktion
führt zu einer Reduzierung der Datenrate, abhängig von der Bildvorlage, bis etwa um den Faktor 12.
Zusammen mit der über DPCM mit Bewegungskompensation vorgenommenen Redundanzreduktion lässt das je nach Bildmaterial eine Datenreduktion bis nahezu um den Faktor 50 zu, ohne dabei wesentlich auf Qualität verzichten zu müssen. In der Praxis kann von einem Faktor zwischen 25 und 40 ausgegangen werden, wie später noch an einem Beispiel gezeigt wird.
5.5 Anwendung der Datenreduktionsverfahren bei der Magnetbandaufzeichnung
Das eigentliche Ziel bei der Datenreduktion ist ein hoher Reduktionsfaktor ohne merkbaren Qualitätsverlust beim wiedergegebenen Signal. Beim Videosignal werden dazu eine Redundanzreduktion mit dem Verfahren der Differenzbildübertragung mit Bewegungskompensation und eine Irrelevanzreduktion unter Zuhilfenahme der DCT vorgenommen. Die Differenzbildübertragung bezieht mindestens zwei oder sogar mehrere aufeinanderfolgende Teilbilder in den Vorgang mit ein. Dies kann aber zu Problemen bei der Bearbeitung von Programmbeiträgen im Studio beim bildgenauen „Schneiden” führen. Somit kann für diesen Fall nur die auf ein Teilbild bezogene DCT zur Anwendung kommen. Um trotzdem eine über die Möglichkeit der DCT und die darauf folgenden Maßnahmen hinausgehende Datenreduktion zu erreichen, wird zusätzlich vorangehend eine Bewegungsschätzung vorgenommen. Das Verfahren der so genannten Intraframe-Codierung kommt zur Anwendung bei allen auf dem DV-Standard basierenden Aufzeichnungsformaten. Dazu gehören für
• semiprofessionelle Anwendung
die Systeme DVund DVCam (u.a. Panasonic, Sony) mit Rasterkonversion von 4:2:2 auf 4:2:0 zur Aufzeichnung und Datenreduktion auf 25 Mbit/s,
• professionelle Anwendung
die Systeme DVCPro25 (Panasonic) und SX (Sony) mit Rasterkonversion von 4:2:2 auf 4:1:1 mit einer Datenrate von 125 Mbit/s und Aufzeichnung mit 25 Mbit/s bzw. 18 Mbit/s und DVCPro (Panasonic) sowie Digital-S (Sony) mit Beibehaltung des 4:2:2- Abtastrasters und Datenreduktion auf 50 Mbit/s.
Bei diesen Systemen für professionelle Anwendung wird zusätzlich über eine Bewegungsschätzung die optimale Wahl der Quantisierungstabellen vorgenommen. In Bild 5.10 wird dies am Beispiel der Codierung bei DVCPro erläutert. Eine weitere Möglichkeit der Datenreduktion und Erhaltung einer nahezu Studioqualität basiert auf der Codierung gemäß dem MPEG-2-Video-Standard mit I-Bildern (Intraframe) oder einer kurzen Gruppe von Bildern (GOP) aus jeweils einem I-Bild und einem zwischen zwei I-Bildern interpolierten B-Bild (bipolar prädiziert), einer so genannten I-B-Gruppe. Zur MPEG-Codierung siehe Näheres im Abschnitt 7.
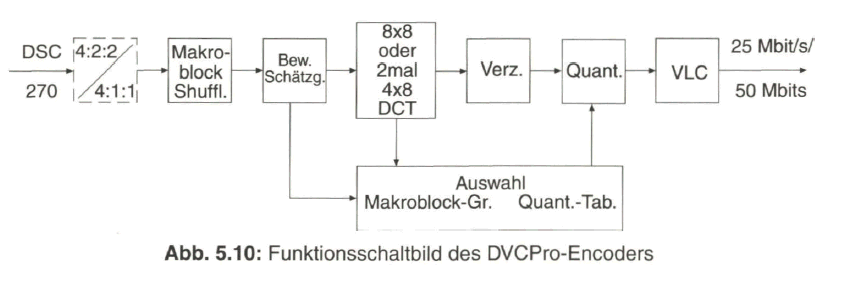
Der aktive Anteil des digitalen Studiosignals DSC 270 wird entweder direkt übernommen (DVCProöO) oder einer Rasterkonversion von 4:2:2 auf 4:1:1 (DVCPro25) unterzogen. Es werden dann Makroblöcke gebildet mit 16 x 16 Pixel (je 4 Blöcke 8x8 Pixel) beim ![]() Signal und dazugehörige Makroblöcke für
Signal und dazugehörige Makroblöcke für ![]() und
und ![]() mit jeweils 8 x 16 Pixel bei DVCPro50 beziehungsweise 8 x 8 Pixel bei DVCPro25. Über ein Shuffling der Makroblöcke eines Teilbildes werden Makroblock-Gruppen gebildet, die sich bezogen auf weniger oder mehr Bewegung innerhalb einer Gruppe unterscheiden. Daraus wird auf DCT in einem 8x8-Pixel-Block (vom Vollbild) oder auf zweimal DCT in 4x8-Pixel-Blöcken (beide Halbbild- Anteile) entschieden. Ergänzend wird über die Bewegungsschätzung eine Auswahl der günstigsten Quantisierungstabelle vorgenommen, die wegen der Bearbeitungszeit in der Bewegungsschätzung auf die verzögert übernommenen DCT- Koeffizienten eingebracht wird. Die nachfolgende Variable Längencodierung (VLC) setzt die statistisch häufiger vorkommenden quantisierten und gerundeten Koeffizienten in kürzere Codeworte um, die seltener vorkommenden Koeffizienten in längere Codeworte, so dass im Mittel eine zusätzliche Datenkompression auf die Aufzeichnungs-Bitrate von 25 Mbit/s bei DVCPro25 beziehungsweise 50 Mbit/s bei DVCPro50 erfolgt.
mit jeweils 8 x 16 Pixel bei DVCPro50 beziehungsweise 8 x 8 Pixel bei DVCPro25. Über ein Shuffling der Makroblöcke eines Teilbildes werden Makroblock-Gruppen gebildet, die sich bezogen auf weniger oder mehr Bewegung innerhalb einer Gruppe unterscheiden. Daraus wird auf DCT in einem 8x8-Pixel-Block (vom Vollbild) oder auf zweimal DCT in 4x8-Pixel-Blöcken (beide Halbbild- Anteile) entschieden. Ergänzend wird über die Bewegungsschätzung eine Auswahl der günstigsten Quantisierungstabelle vorgenommen, die wegen der Bearbeitungszeit in der Bewegungsschätzung auf die verzögert übernommenen DCT- Koeffizienten eingebracht wird. Die nachfolgende Variable Längencodierung (VLC) setzt die statistisch häufiger vorkommenden quantisierten und gerundeten Koeffizienten in kürzere Codeworte um, die seltener vorkommenden Koeffizienten in längere Codeworte, so dass im Mittel eine zusätzliche Datenkompression auf die Aufzeichnungs-Bitrate von 25 Mbit/s bei DVCPro25 beziehungsweise 50 Mbit/s bei DVCPro50 erfolgt.
Das System Digital-S von Sony wurde sehr bald von dem MPEG50 l-frame only abgelöst, das unter dem Sony-Markenzeichen IMX eingeführt wurde. Das Interesse mehrerer ARD-Rundfunkanstalten richtete sich auf die „Vielseitigkeit” von IMX in Bezug auf Einsatzmöglichkeiten, Verwendbarkeit der Cassetten, verschiedene Ausgangssignale und der Möglichkeit, vorhandene Aufzeichnungen mit Magnetaufzeichnungsgeräten der älteren Systeme Beta, BetaSP und DigiBeta auf IMX-Geräten abzuspielen.